최근 AI 이니셔티브를 발표하는 기업이 많죠. 네, AI는 이제 비즈니스의 핵심 전략으로 자리매김하고 있습니다. 그러다 보니 조직 규모가 큰 경우 여러 프로젝트를 동시에 진행합니다. 이런 경우 자연스럽게 컴퓨팅 자원 수요가 급증하죠. 아무리 우선순위 높은 프로젝트라고 해도 AI/ML 모델 구현과 훈련을 위한 자원을 무한정 제공할 수는 없습니다. 이런 경우 모델 구현과 훈련, 최적화 과정을 클라우드에서 이용하는 것도 좋은 대안입니다. 프로덕션 환경 배포 전 단계의 자원 수요를 클라우드를 활용해 민첩하게 제공하는 것이죠. 관련해 최근 데이터 과학자와 AI 개발자들의 관심을 끄는 옵션이 하나 있습니다. 바로 Red Hat OpenShift Data Science입니다.
Open Data Hub 기반 AI as a Service
Red Hat OpenShift Data Science는 완전 관리형 클라우드 서비스입니다. 현재는 Amazon Web Services(Red Hat OpenShift Dedicated 및 Red Hat OpenShift Service on AWS)에서 이용할 수 있습니다. 이 서비스의 근간은 Open Data Hub입니다. 오픈 소스 프로젝트인 이를 기반으로 한 AI as a Service입니다. 참고로 Open Data Hubs는 레드햇 OpenShfit와 Ceph 오브젝트 스토리지 그리고 Kafka, Strimzi, Kubeflow 등을 조합하여 MLOps 환경을 지원합니다. 오픈 소스이다 보니 이를 실제 환경에 구현하는 것은 사용 조직의 몫이었죠. Red Hat OpenShift Data Science는 Open Data Hub를 직접 구축하지 않고도 이용할 수 있는 길을 제시합니다. 완전 관리형 서비스이다 보니 인프라, 플랫폼 뭐 하나 준비할 것이 없습니다. 서비스를 구독해 바로 프로젝트를 시작하면 됩니다.
Red Hat OpenShift Data Science를 주목해야 하는 이유
Red Hat OpenShift Data Science는 단순히 Open Data Hubs 환경을 서비스 형태로 제공하는 것이 아닙니다. 레드햇은 주요 파트너와 ISV의 솔루션을 Open Data Hubs와 통합하여 AI as a Service의 큰 틀을 완성하였습니다. 네, 데이터 수집과 준비, 모델 구현과 훈련, 모델 배포와 모니터링까지 엔드투엔드 수준에서 AI/ML 프로젝트를 지원합니다. 데이터 과학자와 개발자는 인프라와 플랫폼에 대해 신경 쓸 일이 없습니다. 그저 평소 하던 데로 Jupyter 노트북을 쓰면 됩니다. 참고로 파트너 및 ISV가 제공하는 도구는 옵션입니다.
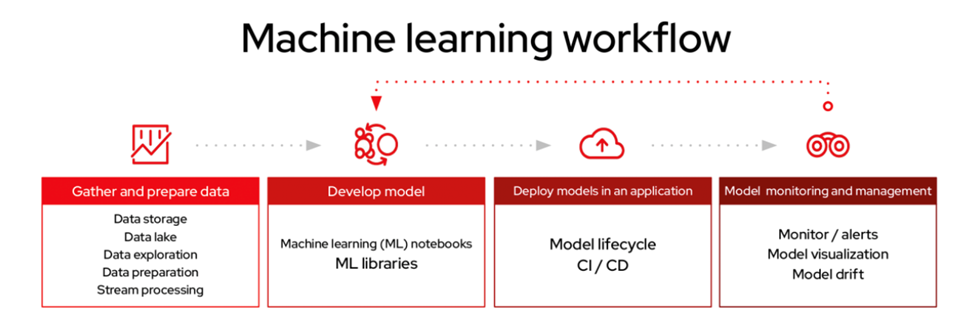
사용자는 Jupyter 노트북으로 모델을 구현하고 이를 훈련할 컨테이너 이미지를 로드할 수 있습니다. TensorFlow, PyTorch, XGBoost, Scikit-learn 등 필요한 라이브러리로 구성한 이미지를 사용해 훈련, 추론 작업을 바로 실행할 수 있습니다. 데이터 준비는 Starburst Galaxy를 이용하면 됩니다. Starburst Galaxy는 하이브리드 클라우드 전반에 걸쳐 있는 데이터에 액세스할 수 있도록 설계된 완전 관리형 플랫폼입니다. 이를 통해 데이터 과학자는 필요한 데이터에 손쉽게 접근할 수 있습니다.
모델 구현 초기 데이터 과학자와 개발자는 모델 재현성 보장에 신경을 많이 쓰죠. 이를 위한 도구가 잘 준비되어 있습니다. Anaconda를 적용하면 필요할 때마다 컴퓨팅 환경을 재현할 수 있습니다. 훈련을 마쳤다면 배포를 해야죠. 이 작업 역시 자동화 기반으로 수행됩니다. Seldon Deploy를 이용하면 모델 배포 및 관리 프로세스를 간소화할 수 있습니다. Seldon Deploy의 강력함은 단순한 관리를 넘어섭니다. 설명 가능한 AI를 위한 모니터링 활동, 카나리아 및 A/B 테스트와 같은 고급 배포 기술로 성능을 최적화하는 방안 등도 지원합니다. Seldon Deploy를 따로 쓰지 않아도 배포 자동화를 할 수 있는데요, OpenShfit의 S2I(Source to Image) 기능을 이용하면 됩니다.
Red Hat OpenShift Data Science 체험하기
Red Hat OpenShift Data Science가 AI/ML 워크플로우를 어떻게 가속하는지 간단히 체험할 수 있습니다. 레드햇은 샌드박스에서 Red Hat OpenShift Data Science를 사용할 수 있는 체험 기회를 제공합니다. 과정은 간단합니다.
1> 레드햇 계정에 로그인한 후 Red Hat OpenShift Hybrid Cloud Console에 접속하여 평가판 클러스터를 생성합니다.
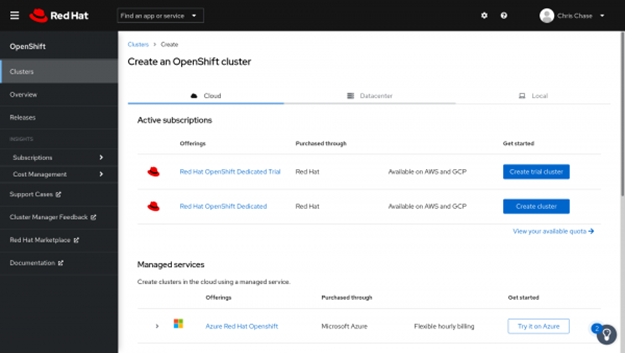
2> 인프라 제공 업체를 선택합니다. 현재 지원되는 AWS를 고르면 됩니다. 이를 위해 AWS 계정이 필요합니다.

3> OpneShfit 클러스터 설정 정보를 입력합니다. 구독과 인프라 유형을 선택하고 AWS 계정 세부 정보를 추가하면 됩니다.

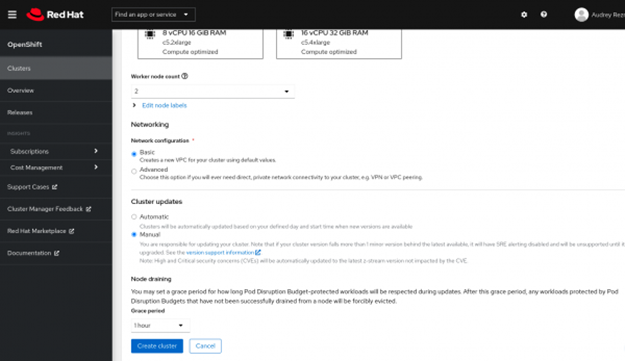
4> 다음으로 작업자 노드 수와 인스턴스 유형을 정의합니다. 참고로 작업자 노드 수는 최소 2개를 선택해야 합니다.

5> 네트워킹 옵션을 구성합니다. 이때 클러스터 업데이트 옵션은 수동을 선택하십시오.
6> 이제 Red Hat OpenShift Data Science를 설치합니다. 이 과정에서 부가 기능을 선택할 수 있습니다. 설치가 완료되면 콘솔에서 보기 메뉴를 선택해 OpenShfit 웹 콘솔로 이동합니다. 그리고 애플리케이션 메뉴에서 Red Hat OpenShift Data Science를 선택하면 됩니다.
이상으로 Red Hat OpenShift Data Science에 대해 알아보았습니다. 더 자세한 내용은 레드햇 개발자 페이지를 참조 바랍니다.
'PRODUCT > Cloud' 카테고리의 다른 글
| 디지털 트윈 시대! Red Hat Enterprise Linux & OpenShift가 뜨는 이유 (0) | 2022.02.16 |
|---|---|
| 하이브리드 멀티 환경에서의 SAP 관리 방안 (0) | 2022.01.12 |
| 10월 Linux & OpenShift 뉴스 하이라이트 (0) | 2021.11.03 |
| 복잡한 하이브리드 아키텍처 수용을 위해 지금 해야 할 일은? (0) | 2021.08.25 |
| OpenShift기반 DevOps/MSA 구축 Part 1. (0) | 2021.05.06 |



